This blog post is dedicated to HAProxy Troubleshooting for vSphere with Tanzu or also known as TKGs. Based on your configuration and deployment and the various items you need to configure you can make mistakes or items are not correctly configured. In my case, there were multiple problems at different deployments with parameters and reachability related to the network. In the end, after all the hours of troubleshooting, I ended up with a list of commands that might help others out. So that is the topic of this blog post.
HAProxy Background
First an introduction about the product HAProxy. HAProxy is a load balancer that is used by vSphere with Tanzu. This is not mandatory but is a product to choose from. The main reason for HAProxy compared to the others is that it is completed free/open-source. The HAProxy OVA is packaged and delivered by VMware and can be found in the following repository. All commands below have been tested against the HAProxy v0.2.0 version (haproxy-v0.2.0.ova) that is at the moment of writing the most recent version available.
Appliance access (SSH)
After a successful deployment, you can access the HAProxy appliance with an SSH session. This session can be established with a tool like PuTTY. The user account that should be used in the root account.
Keep in mind: Do not change configuration unless you absolutely know what you are doing. Almost all the issues I ran into were related to entering incorrect information into the deployment wizard or firewall issues.
Troubleshooting Services
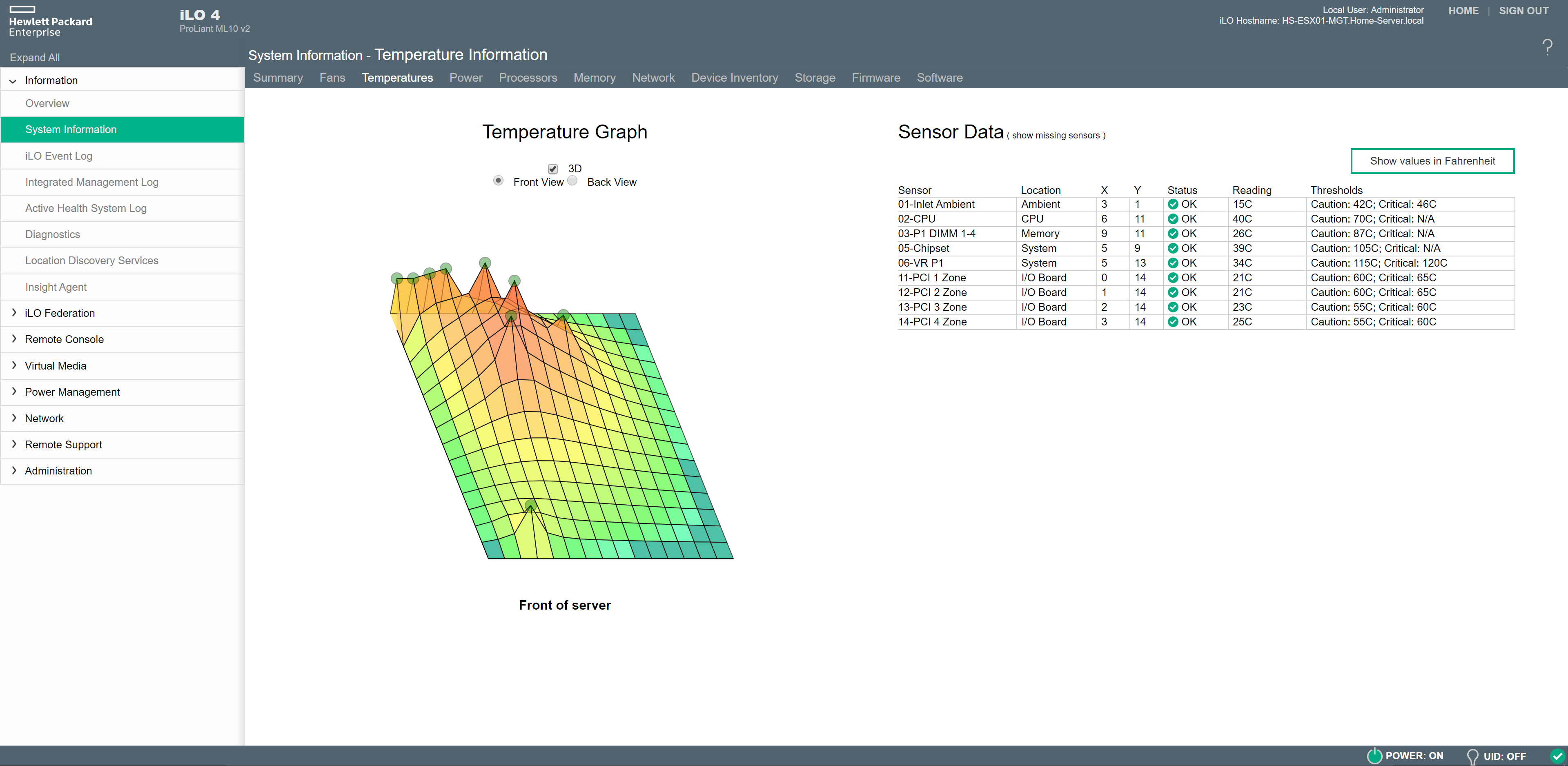
One of the first things to check at first is that all services are running on the HAProxy appliance. When services are not started this is mostly caused by an invalid/incomplete configuration that is filled by the deployment wizard of the OVA.
### Check failed services
systemctl list-units --state=failed
### Check primary services for HAProxy and Tanzu Integration
systemctl status anyip-routes.service
systemctl status haproxy.service
### Restart services
systemctl restart haproxyTroubleshooting Configuration Files
There are multiple configuration files in use by HAProxy here are the most important ones. Also, keep in mind what I already said before… do not change anything unless…
### Anyip-routes configuration file
cat /etc/vmware/anyip-routes.cfg
### HAProxy configuration file
cat /etc/haproxy/haproxy.cfg
### HAProxy dataplane api configuration file
cat /etc/haproxy/dataplaneapi.cfg
### Validation of configuration file
haproxy -c -f /etc/haproxy/haproxy.cfgTroubleshooting HAProxy process output
Sometimes it is good to check the latest messages generated by the HAProxy process. There will be information about the startup of the process and the pool members.
### Show logging
journalctl -u haproxy.service --since today --no-pagerTroubleshooting IP Settings
By entering wrong IP information in the deployment wizard the configuration files surrounding the IP address settings, gateway, etc can be configured incorrectly. What I noticed is there is not really a check inside the deployment that verifies if the address that is entered is valid in any sort of way.
### List IP Settings
ifconfig
### Config files (incase of three NIC configuration)
cat /etc/systemd/network/10-frontend.network
cat /etc/systemd/network/10-workload.network
cat /etc/systemd/network/10-management.network
### Routing check
route
ip routeTroubleshooting Certificates
Certificates files used by the HAProxy application are inside the HAProxy directory on the local system. The certificates are BASE-64 encoded!
### Certificate authority file:
cat /etc/haproxy/ca.crt
### Certificate server file:
cat /etc/haproxy/server.crt
### Certificate URL by default:
https://%HAProxy-Management-IP%:5556Troubleshooting NTP
One of the all-time favorites that are notorious for disrupting IT systems is off course NTP. Here are some commands for troubleshooting on Photon OS.
### Check service status
systemctl status systemd-timesyncd
### Show NTP peers
ntpq -p
### Restart service
systemctl restart systemd-timesyncd
### Configuration file
cat /etc/systemd/timesyncd.confTroubleshooting the HAProxy API
The HAProxy API is used by Tanzu to configure HAProxy for the management and workload components. Authentication is set up when deploying the OVA and the credentials are entered in the wizard. With the second URL you can verify those credentials:
### Info page
https://%IP-address%:5556/v2/info
### Authentication should work with the HAProxy user account (specified in the deployment wizard)
https://%IP-address%:5556/v2/clusterWrapup
Thank you for reading this blog post about HAProxy troubleshooting for vSphere with Tanzu or in short TKGs. I hope it was useful to you! If you got something to add? Have additional tips or remarks please respond in the comment section below.
Have a nice day and see you next time.