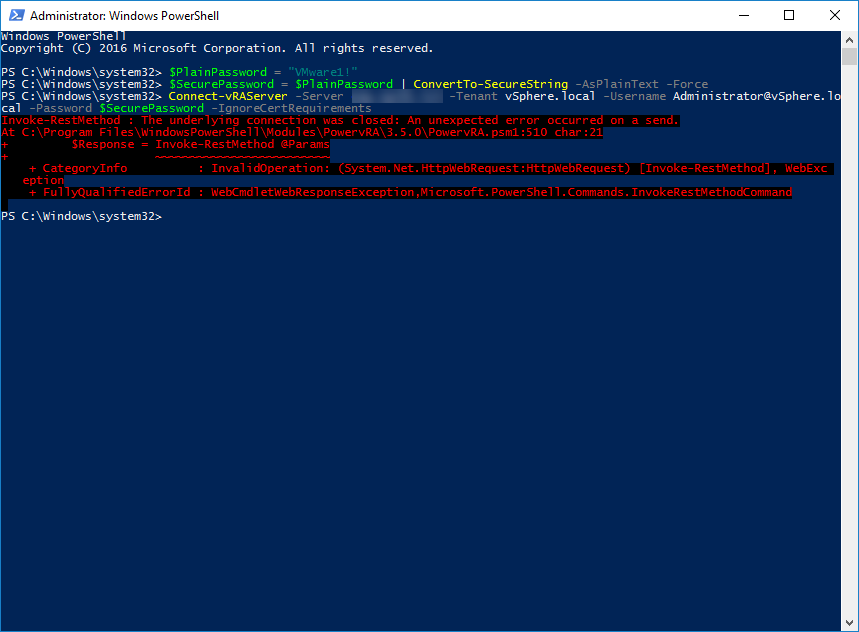
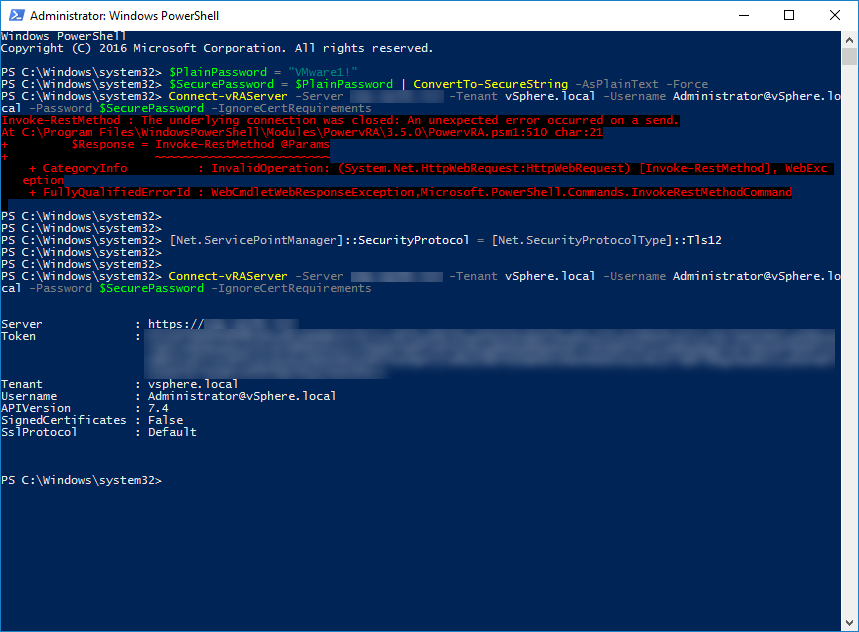
Today I was greeted by the following error message when logging into the VMware vCenter Server also known as VCSA: “Could not connect to one or more vCenter Server systems: https://%fqdn%:443/sdk“. So it was time for a quick write-up on how to resolve this issue.
The issues were already present a couple of hours earlier based on monitoring and logging. For example, Veeam Backup & Replication tried to perform a backup but failed because there were no vSphere Tags available. Veeam Backup & Replication generated the following message “Tag Backup SLA – Bronze is unavailable, VMs residing on it will be skipped from processing.“.
I’m running a VMware vCenter Server as in a VCSA 6.7 appliance and it has an embedded Platform Services Controller. The exact version of the appliance was at the moment of the issue “6.7.0.32000 – Build 14070457“.
Could not connect to one or more vCenter Server systems:
At first glance everything looks fine, the web-interfaces are online, authentication is working but after login, the following message appears “Could not connect to one or more vCenter Server systems: https://%fqdn%:443/sdk“. None of the pages are displaying any content. Here is a screenshot:

After performing a simple reboot nothing had happened, the result was the same. So it was time to dig deeper. Luckily the reboot did trigger a new event in the Appliance Management Page (5480). It appeared that the /storage/seat disk had filled up. The alert that popped-up was “File system /storage/seat is low on database storage space. Increase the size of disk /storage/seat or decrease the data retention.” Here is a screenshot:

Increasing Disk Space
After finding the error message it appeared to be an easy fix. Here is an overview of the commands I used. The commands are also usable for expanding one of the other VCSA virtual disks.
Keep in mind: before increasing disk capacity make sure you have a backup or snapshot available.
It this case we are going to expand this /storage/seat volume. The seat volume is responsible for Stats, Events, Alarms, and Tasks (SEAT) for VMware Postgres (Database).
# Step 01: Connect with the vCenter Server with an SSH Session (use for example Putty).
# Step 02: Login with the root account (root/your-password).
# Step 03: Enable the shell
shell
# Step 04: Run the command to verify the current disk space:
df -h
# Step 05: Increase disk capacity with the Host Client because the vCenter Web-interface is not working ;) (see screenshots)
# Step 06: Run the disk expansion command, the expected output should be: VC_CFG_RESULT=0
vpxd_servicecfg storage lvm autogrow
# Step 07: Verify the disk again, the disk should be bigger!
df -h
# Step 08: Reboot the VCSA
reboot
# Step 09: Verify the working of the VCSA Appliance after reboot.Here is a collection of screenshots of me performing the procedure.





Conclusion
VMware made it easy for the system administrators to identify the issue and quickly expand the virtual disk from the vCenter Appliance. This is a huge improvement compared to the past. The only thing you need to watch out for is the number of virtual disks connected to the VCSA. If you do not watch out you could expand the wrong disk.
The reason that the disk filled up was caused by two things in my case. 1) I created and destroyed lots of virtual machines in the days before the incident. 2) The VCSA is configured as a tiny footprint so that is why the disks are relatively small.
So this was the write-up! If you got any comments or questions please respond in the section below.